新型架构组
异构融合计算
异构融合计算
本小组致力于为新兴应用快速迭代背景下的通用处理器平台赋能。
如果你对高性能计算、加速器设计、数据流感兴趣,希望本页面能耗为你提供你想了解的内容
🔎 观察
随着互联网、大数据和人工智能的高速发展,系统对算力的需求急剧增加,传统CPU计算能力明显无法满足当前需求。各种定制化的加速器、GPGPU纷纷涌现,在通用CPU的管理下为计算系统提供大量算力支持。在百家争鸣的异构系统黄金时代,我们希望可以贡献绵薄之力。
- CPU和硬件加速器之间存在较高的交互延迟,通信开销大从而很难进行较细粒度的协同计算
- 种类繁多的领域专用处理器都需要CPU调度管理,不易于软件编程
- 不同的加速器之间容易存在许多类似的计算部件,都集成在系统中是一种资源的浪费
- 现有加速器只有在任务粒度较大时才会获取到性能收益
🤔 思考
- 把定制硬件放到CPU附近,降低通信延迟,但不能影响到CPU的运行
- 需要统一的指令集系统,数量不能太多,最好能集成不同加速器时不需要修改CPU前端
- 加速器模块功能变简单减少重复,如果第一点延迟问题可以解决,就可以快速调度不同小模块进行配合完成复杂任务
- 解决延迟问题可以使小粒度任务加速器设计成为可能
我们的方案:
一个紧耦合的加速器设计框架,实现了CPU在统一指令集系统下管理加速器,并且二者独立运行的同时可以极低延迟交互,使得CPU细粒度卸载小规模、低延迟任务成为可能。
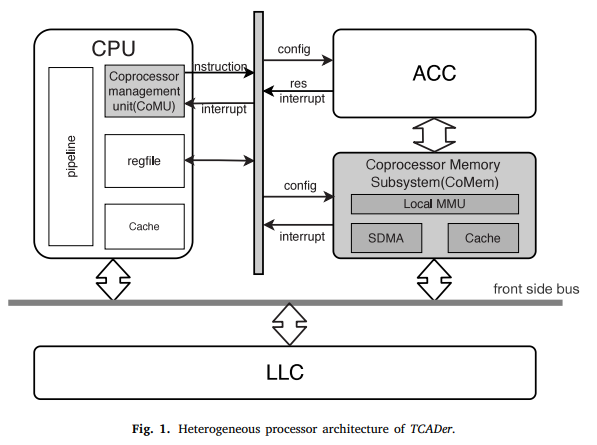
⛳️ 进展
加速器设计软硬件平台,
- 硬件设计可以将CPU和加速器烧录在FPGA上或编译成软件模拟器进行模拟
- linux操作系统可以运行在我们的硬件平台上,并对加速器进行管理
已有加速器族:
- 无损压缩加速器
- 键值存储加速器
- 卷积加速器
- 图像信号处理加速器
- 卷积加速模块(重新优化数据流映射、缓存设计等,进行中……)
⭐️已发表论文




发布于