新型架构组
硬件线程级推测并行系统
线程级推测并行
如果你对并行计算、多核架构、缓存一致性协议感兴趣,希望本页面能为你提供你想了解的内容
🎯 背景知识
随着处理器微架构的设计复杂程度日益增长,优化和提升空间逐渐减小,与此同时制造工艺进步放缓,依靠制程提升处理器性能也难解燃眉之急。如此境遇下,单核架构性能触碰到瓶颈,根据Amdahl定律,使用多核架构并行执行是进一步提升程序效率的有效方式。因此串行程序并行化是有必要的,但是影响并行化的因素并不容易被克服,例如程序自身就不存在可以并行的部分,或者并行化后对于共享资源的访问控制过开销过高。
线程级推测并行是一种多核并行架构,利用多核加速串行执行程序,它将串行程序划分成若干个有序片段,并将这些有序片段运行在多个处理器核上,按照乱序执行顺序提交的方式处理所有片段,如果片段执行失败,则回滚恢复重新执行,直到可以提交为止,保证程序向前推进。并行架构可以使用锁对于并行程序之间的共享资源访问进行控制,其同步开销较大,并且锁住的区域仍然是串行执行的,而线程级推测并行作为无锁并行架构,才能实现串行程序在真正意义上的并行执行。
同时异构计算是当前计算架构演进潮流中的热点,Intel提出的Alder Lake就以性能核(Goldencove)和能效核(Gracement)结合的方式在有限的面积资源下提升处理器多核性能。通常而言,能效核受资源限制,单线程性能必然弱于性能核,但是面积小,可以在相同面积下集成多个能效核,提供多核优势。为了更好地利用能效核的多核并行能力,增加线程级推测并行扩展将提升能效核的整体性能,发挥其多核优势。以Intel 12700平台的大小核为例,
根据Intel公布的版图显示,Goldencove核心的面积大约是Gracement核心的4倍,如果在4个Gracement核心上利用线程级推测并行来执行串行程序能获得比性能核快2倍以上的加速比,那么在能效核上增加线程级推测并行的能力将是有利可图的。
下面着重介绍线程级推测并行的基本概念
线程级推测并行(TLS,Thread-Level Speculation),亦称有序并行(Ordered Parallelism)、多版本缓存(Multi-Versioned Cache)、多版本内存(Multi-Versioned Memory)
从缓存一致性的角度讲,TLS具有的鲜明特征即是Multi-Versioned,作为并行技术,重点关注共享资源的读写控制。这项技术可以追溯到1995年,伴着当时提的火热的CMP,理想情况下一核有难多核支援,但是想让多核用起来,并行编程是个难题,常见的就是加锁,依赖处理器提供的原子操作,但是对于用户程序而言,使用这些调用的代价较高,同时想写出一个高效并且正确的并行程序也很困难,例如死锁问题。因此人们想寻求避免使用锁的方式来并行执行程序,其实本质上就是把原子指令这中原子性粒度局限在一条指令的行为扩展到一个代码片段。虽然利用两条原子指令也可以实现,比如临界区,但是临界区只允许单个线程执行,意味着多核资源的浪费,不符合多核资源最大化利用的原始诉求。
简而言之,程序能否并行执行,取决于资源是否存在冲突,例如共享变量,如果存在多个同时读,不考虑顺序的多个同时写,但是多个顺序写(例如内存一致性,程序序等),则存在违背程序序的可能。因此为了解决这种复杂的场景而提出Thread-Level Speculation,要求在运行期间解决并行程序之间的资源冲突问题。如果把问题缩小,共享资源主要代指内存块,冲突即为load/store操作不符合程序的行为要求,例如:For循环N次,现在有N个核,让N个迭代直接在N核上同时运行,如果迭代之间存在同一个内存块的load/store操作,那么是有可能出错的(迭代i < j,Store j先于Load i发生)。这个例子包含TLS技术实现中重点关注的难点:
- 如何检查出错误
- 如何恢复
关于更多的技术内容在这里不作展开,相信到这里,你已经大致清楚线程级推测并行要达到怎样的目的,更多的内容可以在后续跟进的过程中深入了解,比如:
- Hardware/Software TLS
- Transactional Memory和TLS在实际应用中的关联
- Eager/Lazy conflict detection、eager/lazy versioning、lazy commit
- False sharing、privatilization、word detection
- Spwan programming model, what/why?
- Software/Hardware rollback
- 任务切分、冷启动、缺页异常、编程模型对于硬件设计的辅助性能提升的关系
⛳️ 进展
在之前一年的时间中,已经在Gem5平台搭建出线程级推测并行系统,支持:
- OoO CPU
- Cache Coherency Design
当前处在寻找Benchmark的阶段:
- SPEC2006,排除了lbm、libquantum、milc、h264ref、sphinx3,它们的程序行为不合适,都是parallel的,但是部分在编译器静态期间是分析不出来的(存在指针等影响因素),mcf倒是可以考虑修改一下
- Olden Benchmark,这个是测事务访存的,但是无妨,也是可以用的
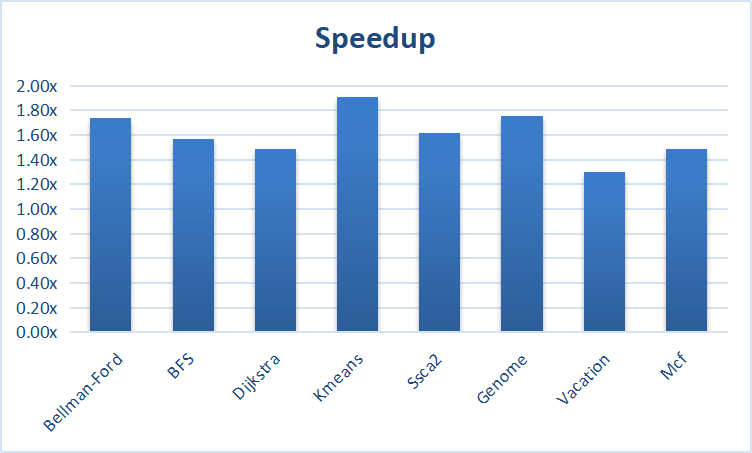
- STAMP,同样是事务访存,目前修改了kmeans,效果理想
- Graph benchmark,这个目前是手写了两个算法,Bellman-Ford和BFS,效果都不是很理想,问题在于编程模型不好使,程序调优有较大的提升空间
快速体验方式参考这里: 如果不想自己搭建环境,想快速体验下,可以通过浏览器上gitlab在repo中手动启动流水线跑ci感受推测并行相较于串行执行的加速效果(如何上gitlab?可以私下沟通) 以下是本地开发环境的配置
- Ubuntu 18/20,如果想用Windows,推荐使用WSL2
- 依赖安装可能需要翻墙
- WSL2配置方法(推荐使用CLion,如果你熟练VScode或者Vim等其他手动搭建环境则忽略CLion配置)
- GEM5配置(推荐额外安装libpng、graphviz库)
- 项目正在开发的分支为TinyTLS
⭐️ 参考资料
文献
💡 帮助




发布于